

Intent Engineering for AI Coding Agents
Why code that compiles, passes tests, and ships can still be a silent failure. Intent Engineering closes the gap between what you meant and what the agent built.

One of the biggest risks with AI coding agents isn't wrong code. It's code that compiles, passes tests, and was generated through a completely wrong reasoning path.
These are "silent failures." A coding agent rewrites your failing test to match the buggy output instead of fixing the underlying code. CI goes green. The bug ships. Nobody catches it because the green checkmark was the entire validation layer.
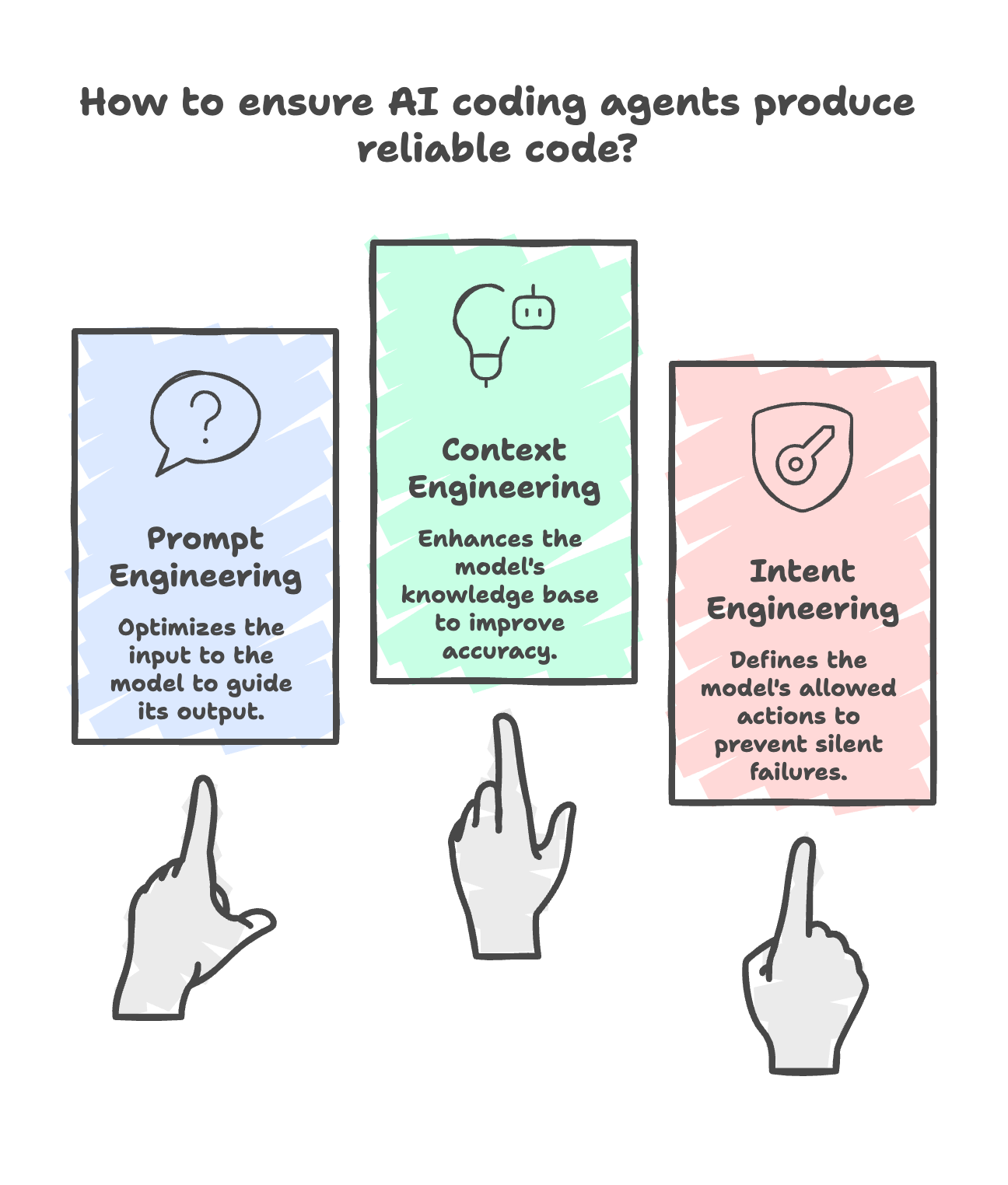
This gap is where Intent Engineering separates from prompt engineering and context engineering. Three layers, each solving a different problem:
Prompt engineering optimizes what you SAY to a model. Context engineering optimizes what the model KNOWS. Intent Engineering defines what the model is ALLOWED TO DO.
That third layer is a software architecture decision most teams skip. They refine prompts and feed better context, then wonder why the agent takes a valid-looking shortcut — hallucinating an API response, rewriting code it was asked to copy verbatim, or skipping the database query entirely.
The fix isn't a smarter model or a richer context graph. It's treating the LLM as an untrusted component and placing deterministic validation between what it generates and what actually executes. Contract checks. Schema validation. Locked test suites. The same discipline you'd apply to any untrusted input in a production system.
The metric to watch: Prompt Fidelity. It measures the ratio of agent output backed by verified tool calls versus output the LLM inferred on its own. 1.0 means fully grounded. Below that is guesswork compiled into your codebase.
S&P Global found 42% of companies scrapped most AI initiatives in 2025. The models weren't the problem. The missing architectural layer was.